Common pitfalls in evaluating model performance and strategies for avoidance in agricultural studies
Benchmarking Biases via Simulated and Real Multi-Season Datasets
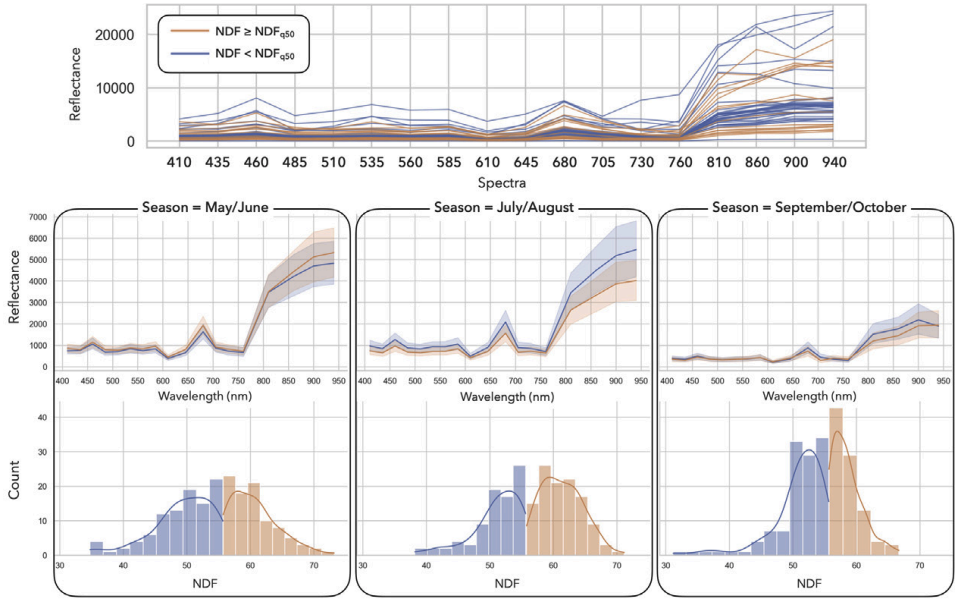
To rigorously quantify model estimation biases in a global setting, the study utilized both a simulated spectral dataset with controlled latent variables and a real-world forage quality dataset collected across multiple seasons. It illustrates the structure of the real-world dataset, characterized by complex seasonal variations and autocorrelation, which served as the foundation for benchmarking how well different evaluation strategies handle environmental block effects.
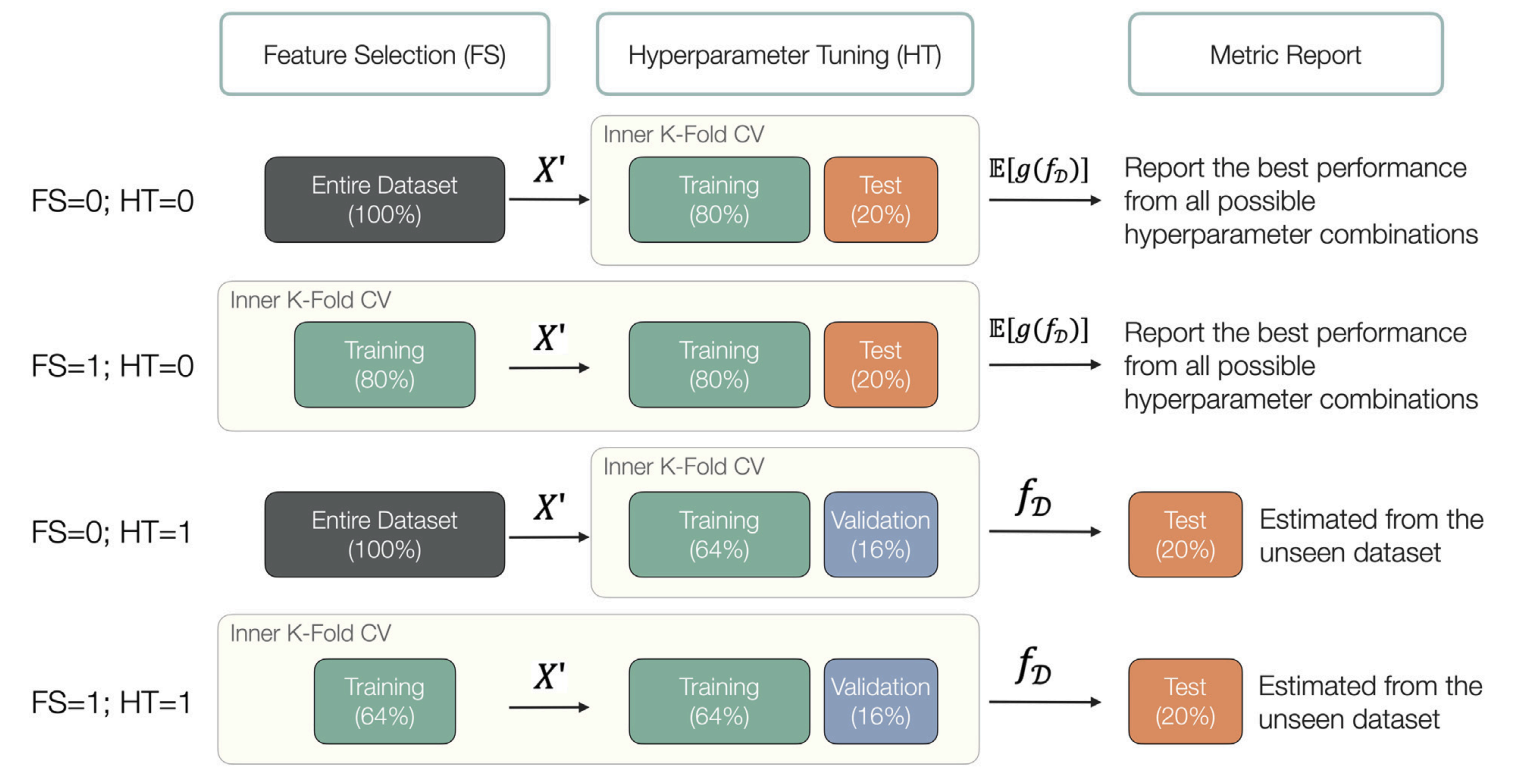
The Impact of Splitting Strategies in Model Selection
The study demonstrates how improper splitting strategies during model selection, such as performing feature selection or hyperparameter tuning on the entire dataset rather than within training folds, lead to significant data leakage and inflated performance estimates. This figure visualizes these distinct workflows (e.g., separating training, validation, and test sets versus mixing them), highlighting the necessity of isolating the model selection process from the final performance evaluation to ensure validity.
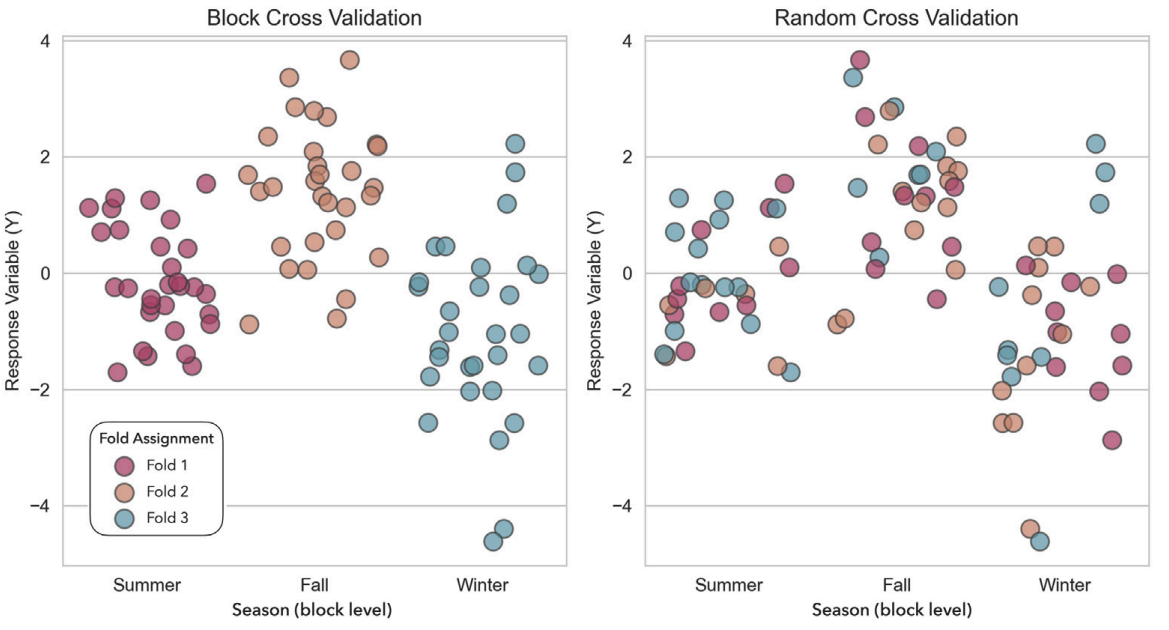
Block Cross-Validation vs. Random Splitting
Ignoring experimental structures, such as seasonal variations or herd differences, causes standard Random Cross-Validation (CV) to overestimate model performance by failing to account for block effects. The figure contrasts these approaches, showing how Block CV respects experimental boundaries (keeping samples from the same block together) to provide a more realistic estimate of a model's generalizability to new, unseen environments.
